Trie (Prefix Tree)
Introduction
Trie is one of the most efficient data structures used for storing large collections of words. Each node stores one character and every path from the root represents a word or prefix. Because common prefixes are shared, Trie saves searching time considerably.
Why Do We Need Trie?
Suppose Google has to search millions of words while providing Auto Complete suggestions. Searching every word one by one would be very slow. Trie allows searching character by character, making prefix searching extremely fast.
Real-Life Example
- Google Search Suggestions
- Mobile Keyboard Prediction
- Dictionary Applications
- Spell Checker
- IP Routing
- DNA Sequence Matching
Properties of Trie
- Stores characters instead of complete words.
- Each edge represents one character.
- Root node contains no character.
- Leaf nodes represent complete words.
- Supports efficient prefix searching.
- Searching depends on word length instead of total words.
Trie Structure

Figure 1 : Trie storing the words CAT, CAR, CARE, DOG and DOT.
| Component | Description |
|---|---|
| Root | Starting node. |
| Edge | Represents one character. |
| Node | Stores one alphabet. |
| Leaf | Represents end of a word. |
| End Marker | Indicates complete word. |
Trie Node Structure
Each node of a Trie stores a single character and maintains pointers to its child nodes. A special flag is used to indicate whether the current node represents the end of a valid word.
| Field | Description |
|---|---|
| Character | Stores one alphabet. |
| Children | Pointers to all possible child nodes. |
| End of Word | Boolean flag indicating completion of a word. |
Insertion in Trie
Insertion starts from the root node. Each character of the word is processed one by one. If a character already exists, the algorithm follows the existing path. Otherwise, a new node is created. Finally, the last node is marked as the end of the word.

Figure 2 : Inserting the words CAT, CAR and CARE into a Trie.
Insertion Example
CAT
CAR
CARE
DOG
DOT
After inserting these words, common prefixes such as CA are stored only once. This reduces memory usage.
Searching in Trie
Searching begins from the root node. Each character of the required word is matched one by one. If every character exists and the final node is marked as the end of a word, the search is successful. Otherwise, the word does not exist.

Figure 3 : Searching the word CARE in Trie.
Searching Example
| Word | Result |
|---|---|
| CAT | Found |
| CARE | Found |
| DOG | Found |
| APPLE | Not Found |
| CART | Not Found |
Deletion in Trie
Deletion removes a word from the Trie without affecting other words sharing the same prefix. Nodes are deleted only when they are no longer required.
Worked Example
| Step | Operation | Result |
|---|---|---|
| 1 | Insert CAT | Create C→A→T |
| 2 | Insert CAR | Reuse C→A |
| 3 | Insert CARE | Add E after R |
| 4 | Search CAR | Found |
| 5 | Delete CAR | Only End Marker Removed |
| 6 | CARE Still Exists | Yes |
Prefix Searching in Trie
One of the biggest advantages of a Trie is its ability to perform prefix searching efficiently. Instead of searching the complete dictionary, the Trie follows the characters of the prefix and immediately reaches all matching words.
Suppose the Trie stores CAT CAR CARE CARD CART DOG DOT
Searching prefix "CAR" returns
- CAR
- CARE
- CARD
- CART
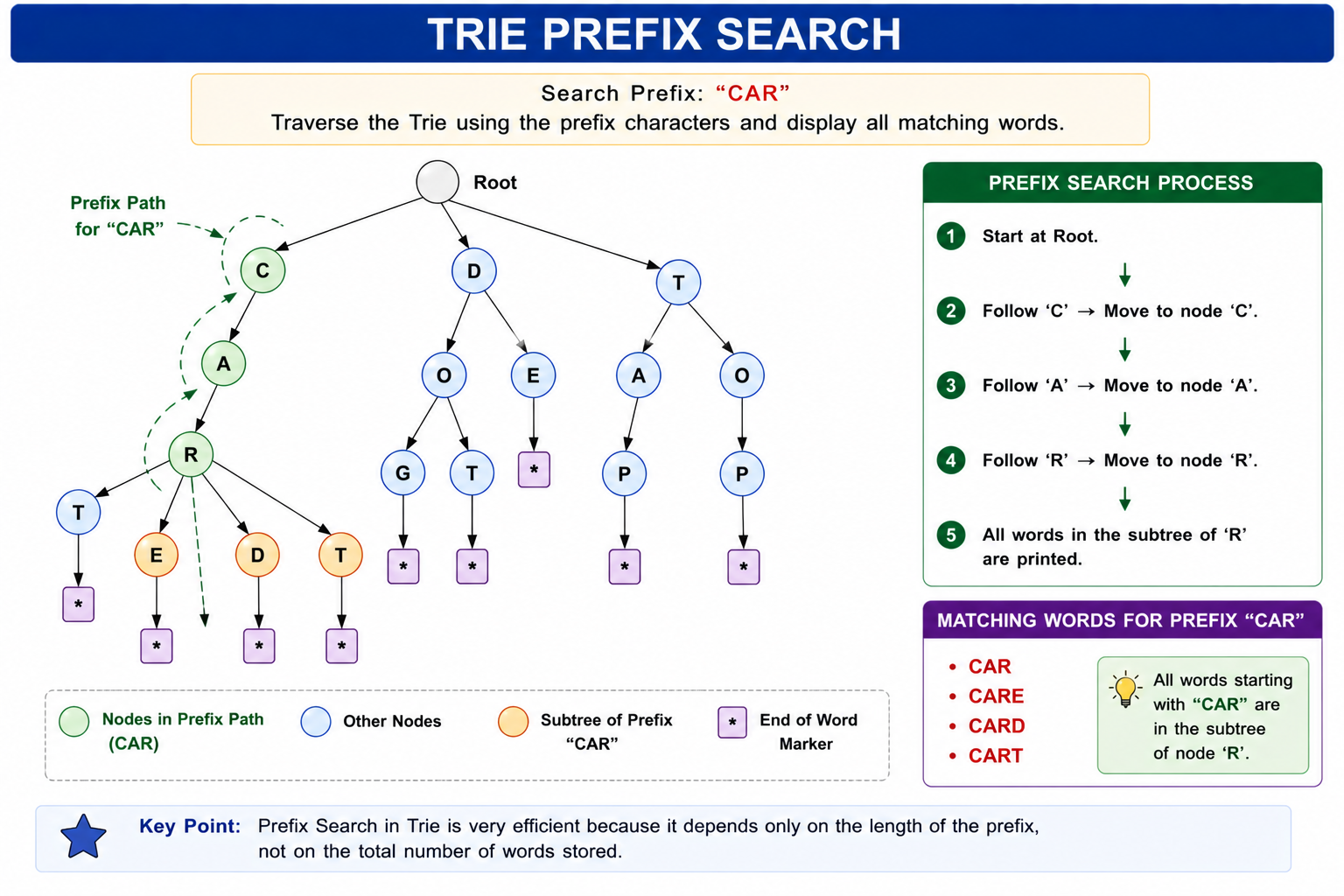
Figure 4 : Prefix Searching in Trie.
Auto Complete Using Trie
Modern search engines and mobile keyboards use Trie to provide Auto Complete suggestions. After typing a few characters, the Trie traverses the subtree and displays all possible matching words.

Figure 5 : Auto Complete Suggestions using Trie.
- CAT
- CAR
- CARE
- CARD
- CART
Longest Prefix Matching
Longest Prefix Matching is widely used in computer networking. Whenever an IP address is received, the routing table searches for the longest matching prefix. Trie makes this operation extremely efficient.
| Destination IP | Matching Prefix |
|---|---|
| 192.168.1.25 | 192.168.1.0/24 |
| 10.10.15.4 | 10.10.0.0/16 |
| 172.16.5.8 | 172.16.0.0/16 |
Deletion Example
Deletion is slightly more complicated because shared prefixes must be preserved.
- CAR
- CARE
- CARD

Figure 6 : Deleting a Word from Trie.
Algorithms Used in Trie
| Algorithm | Purpose |
|---|---|
| Insert() | Insert a new word. |
| Search() | Search an existing word. |
| Delete() | Delete a word safely. |
| PrefixSearch() | Search all matching prefixes. |
| AutoComplete() | Display matching words. |
Time Complexity Analysis
The performance of Trie depends on the length of the word rather than the number of words stored in the dictionary.
| Operation | Time Complexity | Explanation |
|---|---|---|
| Insertion | O(m) | m = Length of the word |
| Searching | O(m) | Traverse one character at a time |
| Deletion | O(m) | Delete unnecessary nodes |
| Prefix Search | O(m) | Locate prefix node |
| Auto Complete | O(m + k) | k = Number of matching words |
| Space Complexity | O(ALPHABET × N × M) | Depends on number of stored characters |
Trie vs Hash Table

Figure 7 : Comparison between Trie and Hash Table.
| Feature | Trie | Hash Table |
|---|---|---|
| Searching | O(m) | O(1) Average |
| Prefix Search | Supported | Not Supported |
| Auto Complete | Very Efficient | Not Suitable |
| Dictionary | Excellent | Good |
| Memory Usage | Higher | Lower |
Trie vs Binary Search Tree
| Feature | Trie | Binary Search Tree |
|---|---|---|
| Stores | Characters | Complete Keys |
| Searching | O(m) | O(log n) |
| Prefix Search | Supported | Difficult |
| Dictionary | Excellent | Moderate |
| Auto Complete | Supported | Not Efficient |
Advantages of Trie
- Fast searching.
- Very efficient prefix matching.
- Excellent for dictionaries.
- Ideal for Auto Complete systems.
- Supports Spell Checker.
- Longest Prefix Matching is easy.
- Searching depends only on word length.
Disadvantages of Trie
- Consumes more memory.
- Implementation is comparatively complex.
- Many pointers increase storage requirements.
- Not suitable for very small datasets.
Applications of Trie
- Google Search Suggestions
- Dictionary Applications
- Spell Checker
- Auto Complete Systems
- Contact Searching
- Search Engines
- IP Routing (Longest Prefix Matching)
- Artificial Intelligence
- Natural Language Processing
- DNA Sequence Searching
Frequently Asked Interview Questions
- What is Trie?
- Why is Trie called a Prefix Tree?
- Differentiate Trie and Binary Search Tree.
- Explain Insertion in Trie.
- Explain Searching in Trie.
- Explain Deletion in Trie.
- What is Prefix Searching?
- What is Longest Prefix Matching?
- Explain Auto Complete using Trie.
- Where is Trie used in real life?
Practice Questions
- Construct a Trie for CAT, CAR, CARE, CARD and CART.
- Illustrate the insertion of the word DOG.
- Explain searching in Trie with an example.
- Explain deletion in Trie with suitable diagrams.
- Differentiate Trie and Hash Table.
- Differentiate Trie and Binary Search Tree.
- Explain Auto Complete using Trie.
- Explain Longest Prefix Matching.
Key Takeaways
- Trie stores characters instead of complete words.
- Searching depends only on word length.
- Prefix searching is highly efficient.
- Common prefixes are shared among multiple words.
- Trie is widely used in search engines and dictionaries.
Summary
A Trie (Prefix Tree) is one of the most efficient data structures for storing and searching strings. By sharing common prefixes, it enables fast insertion, searching, deletion, and prefix matching. Due to these properties, Tries are widely used in search engines, spell checkers, autocomplete systems, dictionaries, IP routing, and many modern text-processing applications.